SQL에서 Index는 최적화에 아주아주 중요하다. Index는 DB의 table에 대한 검색속도를 향상 시켜주는 자료구조이다.
라고 알고는 있었지만 실 사용은 제대로 안 해봤다는 거.. 왜냐하면 DB가 크지 않으니 안 써도 별 차이를 못 느꼈겠지...
하지만 아주 중요하니 정리하고 가겠다. 영상 하나를 정리하는 게 맞는 말이긴 하다.
훨씬 많은 개념들이 있을텐데 차근차근 정리하겠다.
* 참고한 자료의 출처 먼저 밝히겠다. 기가 막히니 다들 한 번씩 보면 좋을 거 같다. (혹시 문제 되면 말해주세요)
DB 인덱스(DB index) !! 핵심만 모아서 설명합니다 !! (31분이 아깝지 않을 겁니다) (youtube.com)
1. Index 사용 이유
SELECT * FROM customer WHERE naem = 'Minsoo';
customer 테이블에는 데이터가 100만 개 정도 들어있다고 가정하자. 그럼 100만 개의 데이터중에서 이름이 Minsoo라는 사사람의 데이터를 찾으려면..? 처음부터 100만 개의 데이터를 뒤져야 한다. 이걸 full scan(table scan)이라고 한다. 이때의 시간 복잡도는 O(N)이다.
근데 index를 쓴다면? 시간 복잡도는 O(logN)으로 훨씬 빨라지게 된다! (B-tree 기반) 즉 1. 조건을 만족하는 튜플을 빠르게 조회하기 위해서 2. 빠르게 정렬(order by)하거나 그룹핑(group by) 하기 위해서 사용된다.
SELECT * FROM employee E JOIN department D ON E.deptno = D.deptno;
WHERE 조건뿐만 아니라 이런 JOIN 조건절에서도 조건(ON 절)이 쓰이는데 이 조건을 빠르게 찾기 위해서도 Index가 쓰인다고 한다.
2. Index 문법
2-1. index 생성
| id | name | team_id | backnumber |
위와 같은 player 테이블이 있고, 아래와 같은 SELECT문이 있다고 가정하자.
SELECT * FROM player WHERE name = "Minsoo";
그럼 name에 index를 걸어줄 건데 name은 중복된 값이 올 수 있다는 걸 알아야 한다. index 생성 문법은 아래와 같다.
CREATE INDEX player_name_idx ON player (name);
인덱스를 생성하는 문법이다.
다른 예시를 보자. 조건을 보면 같은 팀 안에서 등 번호는 UNIQUE 하게 배정되기 때문에 선수들을 UNIQUE 하게 식별할 수 있다.
SELECT * FROM player WHERE team_id = 105 AND backnumber = 7;
그럼 성능 향상을 위해 Index를 만들 때 team_id와 backnumber를 합쳐서 하나의 index로 만들면 된다.
CREATE UNIQUE INDEX team_id_backnumber_idx ON player(team_id, backnumber);
이렇게 2개 이상의 속성으로 이루어진 index를 multicolumn index 또는 composit index라고 부른다.
근데 위 예시들은 table이 이미 생성돼 있고, 데이터가 들어있는 상태에서 index를 생성하는 방법이고, table을 생성할 때 index도 같이 생성하는 방법에 대해 알아보겠다.
CREATE TABLE player(
id INT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
team_id INT,
backnumber INT,
INDEX player_name_idx(name),
UNIQUE INDEX team_id_backnumber_idx(team_id, backnumber)
);
table을 생성할 때 index를 만들면 index명은 자동으로 만들어주기 때문에 생략해도 된다.
그리고 PRIMARY KEY를 생성하면 RDBMS들이 Index를 자동으로 생성해 준다.
2-2. index 조회
보면은 한 table에 index가 여러 개 존재할 수 있다. 그럼 어떤 index가 있는지 확인하는 문법은 다음과 같다.
SHOW INDEX FROM player;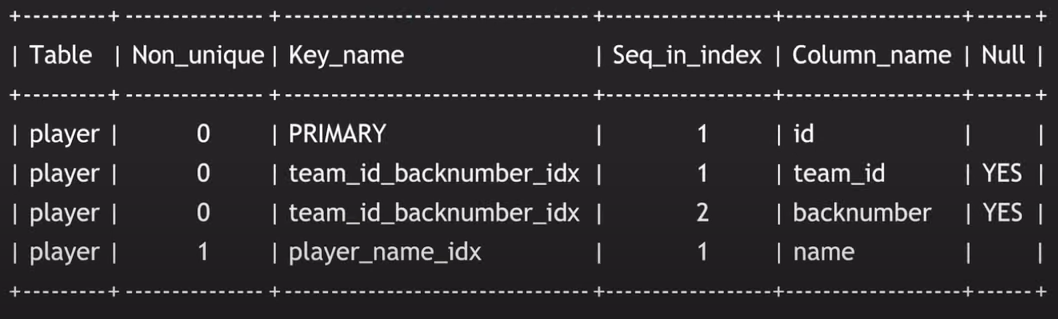
그럼 이런 식으로 table에 있는 index 정보들이 나온다고 한다. ( 더 많은 정보가 나오지만 중요한 정보만 나타냈다고 한다.)
multicolumn index의 경우 Seq_in_index에 번호가 부여된 걸로 속성을 구분할 수 있다.
3. B-Tree 기반 index
index에 대해 알아보다 보면 대부분 B-Tree기반으로 인덱스를 저장한다고 나올 것이다. 그럼 B-Tree 기반으로 index를 저장하는 게 어떤 건데?
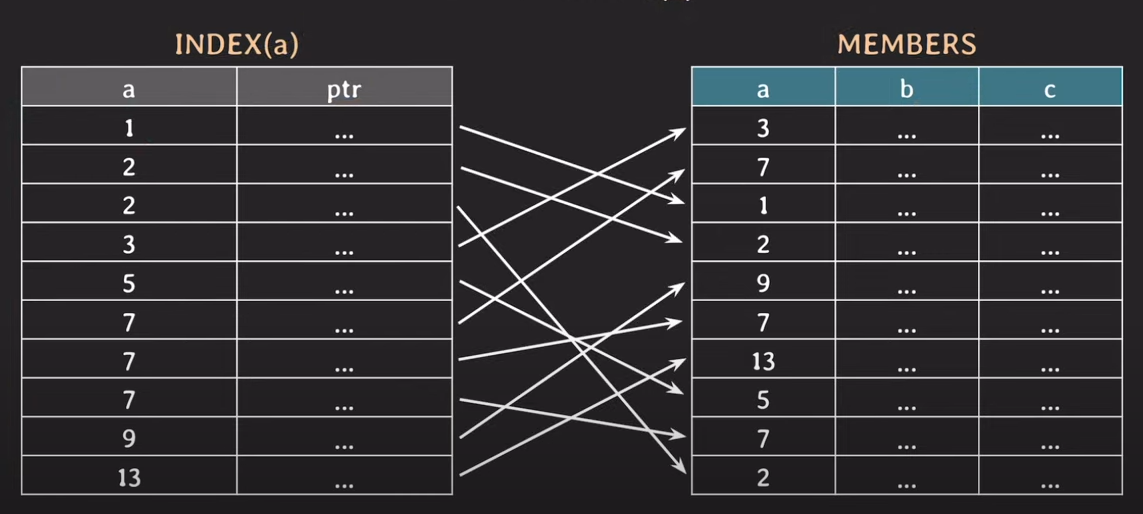
만약 a라는 속성에 대한 INDEX를 생성한다고 2가지 데이터를 가지고 있다. 치면 a에 대한 값들이 작은 값부터 정렬이 된 형태로 저장이 된다. 그리고 포인터라는 데이터를 가지고 있다. 포인터 값은 실제 table(MEMBERS)의 어떤 값과 연관되어 있는지 정보를 가지고 있다.
그래서 왜 Index를 사용하면 검색 시간이 짧아지는 건지..? 값이 정렬이 돼있긴 하지만 처음부터 찾아보면 결국 똑같은 거 아닌가..? 싶죠
INDEX에서는 Binary Search(B.S)를 하게 된다. 역시 예시로 이해하는 게 젤 쉬운 거 같다.
WHERE a = 9; 이 조건에 해당하는 값을 찾을 때 INDEX에서는 중앙에 있는 값 하나를 가져온다. 처음엔 5가 되겠죠? 그럼 5랑 9를 비교해 보면 9가 더 크기 때문에 5 이하에 있는 값들은 검색 범위에서 제외되는 거죠! 근데 아직 못 찾았잖아요? 남은 부분에서 다시 중앙값을 가져와요 그럼 7입니다. 7과 9를 비교해서 마찬가지로 7 이하 값들은 제외됩니다. 그럼 또 중앙값을 선택하면 9가 선택되고 만족하는 값이기 때문에 (동일한 9가 있을 수도 있는데 다음 값이 13이라 제외된다.) 종료된다.
요약해 보면
1. 인덱스에서 중앙값을 가져와 조건과 비교해서 확인할 필요 없는 부분은 제외한다.
2. 조건에 만족하는 값을 찾을 때까지 반복한다.
다른 예제를 살펴봅시다.
WEHRE a = 7 AND b = 95;라고 해봅시다. 그럼 이제 중앙값인 5 이하는 제외되겠죠? 여기서 시작합시다.

이제 남은 부분에서 중앙값을 선택해 보면 7입니다. 동일하네요? 근데 b조건도 있는지 확인해 봐야 되잖아요? 하지만 index에는 a 값 밖에 없어요. 그럼 이제 포인터에 들어있는 정보를 이용해 실제 table로 넘어가서 b의 값을 확인해야 합니다. 이해하셨나요? 근데 심지어 7이 하나만 있는 게 아니에요 index에서 위아래로 계속 보면서 7이 더 있는지 살펴보고 더 있으면 또 table에 가서 b 값을 확인해봐야 하죠.
이게 무엇을 의미하냐면 index에서 조건에 해당하는 값들내에서는 table에 가서 full scan을 해줘야 한다는 말이에요. 이 말은 성능적으로 효율적이지 않다는 말이 됩니다.
사실 예상하셨지만 해결은 a와 b 값이 존재하는 INDEX가 있으면 됩니다.
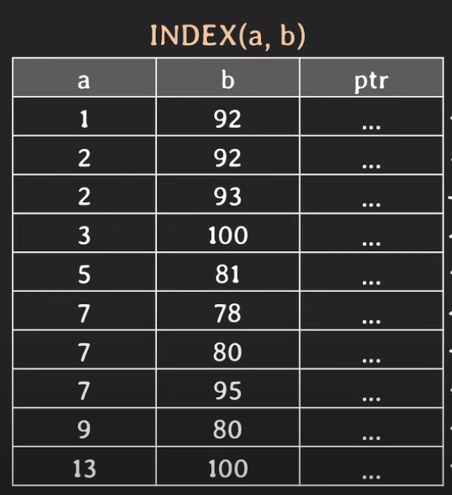
a와 b를 포함하는 INDEX를 생성한 결과입니다. 주의할 점은 속성이 여러 개라면 생성할 때 선언한 속성들 순서로 정렬이 된다는 겁니다. (a, b 중에 a가 먼저니까 a로 먼저 정렬이 되고 b로 정렬이 된다.) 아까는 a값이 7인걸 모두 찾아서 table에서 확인했죠? 이제는 a값과 7을 비교하고, 일치하면 b값과 95를 비교해서 일치하지 않으면 바로 검색 대상에서 제외시킬 수 있는 거죠! (왜냐하면 a=7, b=80인 튜플을 비교해 보면 a는 일치하지만 b는 95보다 작으니 그 이전 데이터들도 제외시킬 수 있다는 거죠. 왜? 작은 값부터 순서대로 정렬했으니까!)
* 주의할 점은 a, b 값을 가지고 있는 INDEX에서 WHERE b = 95; 조건을 찾으려고 하면 b값은 a값을 기준으로 정렬돼 있지 b값으로 정렬된 게 아니라서 성능이 나오지 않는다.
* 만약 b 값을 검색 할 INDEX가 존재하지 않다면 table에서 full scan을 하게 된다.
4. Index 설정
만약 team_id와 backnumber를 포함한 INDEX와 backnumber로만 이루어진 INDEX가 있다고 가정해보자. 그럼 WHERE backnumber = 7; 조건을 찾을 때 어떤 인덱스를 이용할까? (team_id, backnumber) 인덱스는 효율이 나오지 않는다고 해서 backnumber만 가지고 있는 인덱스를 썼으면 좋겠는데.. 할 때 어떤 인덱스를 이용하는지 확인할 수 있는 방법이 있다.
EXPLAIN SELECT * FROM player WHERE backnumber = 7;
이런식으로 확인할 수 있는 정보가 나온다. (더 많은 정보를 가지고 있다.) backnumber만 가지고 있는 index에서 효율좋게 찾고 있는걸 확인할 수 있다.
왜..? 나는 어떤 인덱스를 쓰라고 명시해주지 않았는데?
DBMS에 존재하는 optimizer가 알아서 적절하게 index를 선택해주기 때문에 걱정할 필요가 없습니다.
어 나는 다른 index를 쓰게 하고 싶은데?
SELECT * FROM player USE INDEX(backnumber_idx) WHERE backnumber = 7;
이렇게 인덱스 명을 지정해주면 되는데 약간 권장 사항의 느낌이라고 한다. 이 인덱스를 써주세요.. 느낌? (지정한 인덱스를 안쓰면 full scan으로 동작한다.)
그럼 그냥 무조건 이 인덱스를 써주세요! 도 있지 않을까?
SELECT * FROM player FORCE INDEX (backnumber_idx) WHERE backnumber = 7;
있다! 물론 얘도 인덱스 없으면 full scan으로 동작한다.
SELECT * FROM player IGNORE INDEX (backnumber_idx) WHERE backnumber = 7;
이렇게 쓰면 이 인덱스는 제외시켜줘~ ㅎㅅㅎ
5. Covering Index
조회하는 속성(attributes)을 index가 모두 cover할 때 Covering Index라고 한다.
SELECT team_id, backnumber FROM player WHERE team_id = 5;
이 쿼리를 실행한다고 치자.
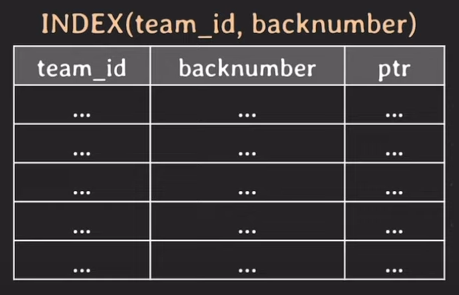
그럼 이 INDEX만으로도 충분하다는 얘기다. 왜냐? team_id로 검색해서 team_id와 backnumber를 조회할건데 INDEX에 다 있으니까 table까지 갈 필요가 없다는 거지
당연히 조회 성능이 더 빠르다.
6. Hash Index
아까 B-Tree Index 알아봤는데 사실 검색해보면 B-Tree와 많이 나오는데 Hash Index도 많이 나오는걸 볼 수 있다.
- Hash니까 당연히 Hash table을 사용합니다.
- 시간복잡도 O(1)의 성능으로 매우 빠른것을 알 수 있다.
- rehashing에 대한 부담
- Hash table은 Array를 이용해서 저장이 되는데 데이터가 계속 추가되면 데이터 크기를 늘여줘야 한다.
- equality 비교만 가능( = , != ) range 비교 불가능 ( > , <= 등)
- multicolumn index의 경우 전체 속성에 대한 조회만 가능하다.
- INDEX(a,b)가 있으면 B-Tree는 a만 이용해서 조회가 가능한데 Hash는 불가하다.
7. Index 주의점
- 한 table에 존재하는 Index는 table에 INSERT, UPDATE, DELETE가 일어날 때마다 Index도 변경이 발생하게 된다.
- 인덱스를 만들면 포인터값과 같은 인덱스를 위한 데이터가 생기니까 추가적인 저장 공간을 차지하게 된다.
- 불필요한 인덱스는 만들지 않는게 중요하다.
- table에 데이터가 조금 있을 경우 Full scan이 더 좋을 수 있다.
- 조회하려는 데이터가 table의 상당 부분을 차지할 때 Full scan이 더 좋을 수 있다.(예를 들어 table에 name 이 '김'인 데이터가 많을 때) -> Full scan을 이용할 지는 optimizer가 판단한다.
- MySQL의 경우 FOREIGN KEY에 자동으로 INDEX가 생성되지만 다른 RDBMS는 그렇지 않은 경우도 있다.
- 이미 table에 데이터가 몇 백만 건 이상 있는 테이블에 인덱스를 생성하는 경우 시간이 오래 걸리고 DB 성능에 영향을 줄 수 있다.
'SQL' 카테고리의 다른 글
| [Oracle] 숫자 내장 함수 (0) | 2024.06.15 |
|---|---|
| [Oracle] 문자열 내장 함수 (0) | 2024.06.15 |
| [Oracle] 기초 (MySQL과의 소소한 차이) (0) | 2024.06.08 |
| [MySQL] Join 알아보기 + 집합 연산 + 서브쿼리 (0) | 2024.06.01 |
| [MySQL] SQL 기본 다지기 (0) | 2024.05.30 |

