사실 내가 제일 좋아하는 부분은 SQL 쿼리문 짜기이다.. 물론 DB가 복잡할수록 어렵지만 그나마 제일 흥미로운 부분이다. 그래서 SQLD 자격증의 존재를 알고 땄었는데 (SQLP는 .. 일단 너무 비싸..) 또 또 또 시간이 지나고 자주 안 쓰다 보니 헷갈려서(복잡한 건 다 까먹었다..) 다시 기본 쿼리문부터 다져보려고 한다. 오라클이랑 MySQL이랑 살짝 다른데 MySQL부터 정리해 보겠다. 이왕 하는 거 되는대로 다 정리해 보겠다. 양이 많아 따로 정리할 수도

SQL 분류
- DDL (데이터 정의어) : 테이블이나 관계의 구조 생성 CREATE, ALTER, DROP
- DML (데이터 조작어) : 테이블에서 데이터를 검색, 삽입, 수정, 삭제하는 데 사용 SELECT, INSERT, UPDATE, DELETE
- DCL (데이터 제어어) : 데이터의 사용 권한 관리 GRANT, REVOKE
1. 테이블 정의 (CREATE)
CREATE TABLE table1 (
column1 INT PRIMARY KEY AUTO_INCREMENT, // 자동 증가
column2 CHAR(10) NOT NULL, // NULL 불가
column3 VARCHAR(10) UNIQUE, // 중복된 값 불가
column4 INT DEFAULT 10, // 기본값 설정
fcolumn INT,
FOREIGN KEY(fcolumn) REFERENCES table2(fcolumn) // 외래키 설정
);
1-1. Key 개념 및 종류
- 기본키 - 후보 키들 중에서 선택한 Main Key (NOT NULL, UNIQUE)
- 후보키 - 기본키가 될 수 있는 키
- 대체키 - 후보키에서 기본키를 제외한 키
- 슈퍼키 - 속성들의 집합으로 이루어진 키로 유일성은 만족하지만 최소성은 만족하지 못한다.
- ex) 이름 + 주민번호가 슈퍼키인 경우 다른 튜플과 구분이 가능하지만 이름만으로는 구분하지 못한다.
- 외래키 - 관계를 맺고 있는 테이블의 참조 속성
- ex) table1이 table2의 fcolumn을 참조하고 있으면 fcolumn은 table2의 기본키
- 참조되는 키는 반드시 UNIQUE나 PRIMARY KEY가 설정되어 있어야 한다.
1-2 제약조건
CONSTRAIN fk_table2 FOREIGN KEY(fcolumn) REFERENCES table2(fcolumn); // 제약조건 이름 설정
FOREIGN KEY(fcolumn) REFERENCES table2(fcolumn) ON UPDATE CASCADE ON DELETE RESTRICT;
- CONSTRAIN은 제약조건의 이름을 명시해 줌으로써 제약조건의 참조가 쉬워진다.
| CASCADE | 참조되는 테이블(부모키)에서 수정, 삭제가 이루어지면 참조하는 테이블(외래키)에서도 동일하게 이루어진다. |
| SET NULL | 참조되는 테이블에서 수정, 삭제가 이루어지면 참조하는 테이블의 데이터는 NULL로 변경된다. |
| NO ACTION | 참조되는 테이블에서 수정, 삭제가 이루어져도 참조하는 테이블의 데이터는 변경되지 않는다. |
| SET DEFAULT | 참조되는 테이블에서 수정, 삭제가 이루어지면 참조하는 테이블의 데이터는 기본값으로 설정된다. |
| RESTRICT | 참조하는 테이블의 데이터가 남아있으면, 참조되는 테이블의 데이터를 수정, 삭제할 수 없다. |
2. 테이블 수정 (ALTER)
ALTER TABLE table1 ADD COLUMN new_column INT; // 테이블에 컬럼 추가
ALTER TABLE table1 MODIFY COLUMN new_column CHAR(10); // 컬럼 타입 변경
ALTER TABLE table1 CHANGE COLUMN column1 new_column1 VARCHAR(10); // 컬럼 이름 변경
ALTER TABLE table1 DROP COLUMN new_column; // 컬럼 삭제
ALTER TABLE table1 table1 ADD (CONSTRAIN table1_pk) PRIMARY KEY column1 // 제약조건 추가
ALTER TABLE table1 DROP CONSTRAIN table1_pk // 제약조건 삭제
ALTER TABLE table1 RENAME new_table1 // 테이블명 바꾸기
- 테이블명 변경은 RENAME 명령어를 이용할 수도 있다.
RENAME TABLE table1 TO new_table1
RENAME TABLE table1 TO new_table1, table2 TO new_table2 // 여러 테이블 변경
3. 테이블 삭제 (DROP) + TRUNCATE
DROP table table1 // 테이블 삭제
DROP DATABASE db // 데이터베이스 삭제
TRUNCATE TABLE table1 // 테이블의 모든 내용 삭제 (복구 불가, 테이블 구조만 남아있음)
4. 테이블 조회 (SELECT)
SELECT * FROM table1
SELECT * FROM table1 WHERE name = 'aaa'; // name이 'aaa'인 튜플 조회
SELECT * FROM table1 WHERE name LIKE '%a%' // name에 'a'가 들어가는 튜플 모두 조회
SELECT * FROM table1 ORDER BY name DESC; // name 컬럼을 내림차순으로 정렬해서 조회 (기본은 ASC)
SELECT name, id FROM table1; // table1에서 name과 id만 조회- 진짜 간단한 select문이야 쉽지.. 복잡해지면 진짜 머리 아프다. 제일 중요한 게 일단 실행 작동 순서를 알아야 한다.
- FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY (기본적인 순서)
- FROM -> ON -> JOIN -> WHERE -> GROUP BY -> CUBE | ROLLUP -> HAVING -> SELECT -> DISTINCT -> ORDER BY -> TOP (구체적인 순서)
4-1. LIKE - 문자열 내에서 원하는 문자열을 찾는 함수
SELECT * FROM t1 WHERE name LIKE 'A%' // A로 시작하는 name
SELECT * FROM t1 WHERE name LIKE '%A' // A로 끝나는 name
SELECT * FROM t1 WHERE name LIKE '_A%' // 두 번째 글자가 A인 name
SELECT * FROM t1 WHERE name LIKE '__' // 두 글자인 name
SELECT * FROM t1 WHERE name NOT LIKE '%A%' // A를 포함하지 않는 name
4-2. 비교연산자 (다른 연산자도 많은데 일단 자주 쓰이는 거만)
SELECT * FROM t1 WHERE name IS NULL; // NULL인 name
SELECT * FROM t1 WHERE name IS NOT NULL; // NULL이 아닌 name
SELECT * FROM t1 WHERE sal BETWEEN min AND max; // min보다 크거나 같고, max보다 작거나 같은 sal
SELECT * FROM t1 WHERE sal NOT BETWEEN min AND max;
SELECT * FROM t1 WHERE address IN('서울','경기'); // 서울 또는 경기인 address // address = '서울' OR address = '경기' 와 같다.
SELECT * FROM t1 WHERE address NOT IN('서울','경기');
SELECT * FROM t1 WHERE sal = ANY(10,20) // sal = 10 OR sal = 20
SELECT * FROM t1 WHERE sal < ANY (10,20) // sal < 10 OR sal < 20
SELECT * FROM t1 WHERE sal = ALL(10,20) // sal = 10 AND sal = 20
SELECT * FROM t1 WHERE sal > ALL(10,20) // sal > 10 AND sal > 20
4-3. 집계함수 - COUNT, SUM, AVG, MIN, MAX
SELECT COUNT(*) FROM t1; // NULL 값인 필드가 있어도 포함
SELECT COUNT(name) FROM t1; // NULL인 name은 개수에 포함 X
SELECT DISTINCT address FROM t1; // 중복된 address 제거
SELECT COUNT(DISTINCT address) FROM t1 // 중복된 address를 제외한 address 개수
4-4. GROUP BY / HAVING
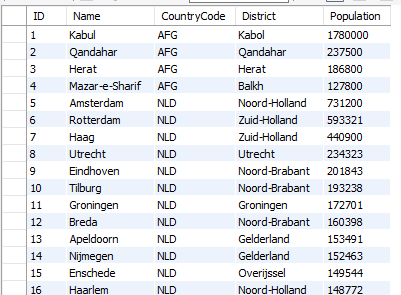
SELECT CountryCode, COUNT(*) FROM city GROUP BY CountryCode;
// 가장 기본으로 CountryCode로 그룹화 해서 각 그룹별 개수를 나타낸다.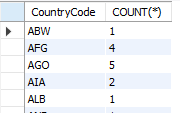
SELECT CountryCode, sum(Population) FROM city GROUP BY CountryCode;
// Code로 그룹화해서 각 그룹별 인구의 총 합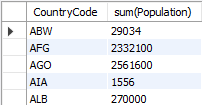
SELECT CountryCode AS Code, District, ROUND(AVG(Population),2) AS avg_p FROM city GROUP BY 1,2;
// 나라별 각도시 평균 인원 수
// GROUP BY 1,2 는 1열(Code)와 2열(District)을 나타낸다.
SELECT CountryCode, COUNT(*) FROM city WHERE Population > 500000 GROUP BY CountryCode HAVING COUNT(*) > 3;
// 1. population > 500000에 일치하는 데이터만 추출
// 2. CountryCode(나라)를 기준으로 그룹화
// 3. 각 그룹별(나라별) 인구(population)가 500000이 넘는 도시가 3개보다 많아야 함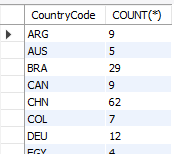
SELECT if(Population >= 500000, 'yes','no') AS '인구수가 50만 이상인가요?', COUNT(*) FROM city GROUP BY 1;
// if(Population >= 500000)이 참일때 값 yes, 거짓이면 no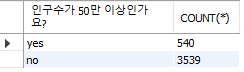
4-5. 조건문 + NULL 처리
SELECT IF (coumn1 > coumn2, 'TRUE', 'FALSE') AS RESULT;
// 참이면 값이 TRUE로 거짓이면 FALSE로 들어간다.
SELECT IFNULL(coumn1, '대체 값') FROM table1;
// coumn1의 값이 NULL이면 대체 값으로 바뀌어서 들어간다.
SELECT ISNULL(coumn1) AS RESULT;
// coumn1의 값이 NULL이면 1을 NULL이 아니면 0을 반환한다.
SELECT
CASE
WHEN id = 1
THEN '사장'
WHEN id = 2
THEN '직원'
ELSE '손님'
END
FROM table1;
// switch case문과 똑같다.
SELECT COALESCE(column1, column2, ... , '대체 값');
// NULL이 아닌 첫 번째 인수를 반환한다. 모든 인수가 NULL이면 대체 값을 반환 한다.
5. 레코드(행) 추가 (INSERT)
INSERT INTO table1 VALUES(value1, value2, value3); // 컬럼 생략 시 모든 열에 대응하는 값을 동일한 순서로 할당해야함.
INSERT INTO table1 (column1,column3) IVALUES (value1, value3); // 일부 컬럼만 넣을 시 컬럼 명시 해줘야 함.
INSERT INTO table1 VALUES (value1, value2, value3), (value11, value22, value33); // 여러개를 한번에 추가 가능
6. 테이블 값 수정 (UPDATE)
UPDATE table1 SET name = 'new_name'; // 모든 name을 바꿈
UPDATE table1 SET name = 'new_name', address = '경기' WHERE id = 1;
// id는 1인 사람의 name과 주소를 바꿈
7. 테이블 값 삭제 (DELETE)
DELETE FROM table1; // table1 데이터 모두 삭제 (복구 가능 = 데이터 용량은 안줄어든다.)
DELETE FROM table1 WHERE id = 1; // id는 1인 레코드 삭제
8. 권한 부여 (GRANT)
CREATE USER 'username'@'localhost' IDENTIFIED BY 'password'; // username이라는 사용자 생성
GRANT ALL (PRIVILEGES) ON *.* TO 'username@localhost' WITH GRANT OPTION;
// username사용자에게 데이터베이스와 테이블에관한 모든 권한을 부여하며 다른 사용자에게도 권한을 부여할 수 있다.
GRANT SELECT, INSERT ON database_name.table_name TO 'username'@'localhost';
// username에게 특정 테이블에 관해 SELECT와 INSERT 권한을 부여한다.
SHOW GRANTS FOR 'username'@'localhost'; //권한 조회
9. 권한 취소 (REVOKE)
REVOKE ALL ON database_name.* FROM 'username'@'localhost';
// username에게 부여된 database_name 데이터베이스의 모든 권한을 취소한다.
// 만약 WITH GRANT OPTION으로 username이 다른 사람에게 권한을 부여했으면 그 사람의 권한도 취소된다.
'SQL' 카테고리의 다른 글
| [Oracle] 숫자 내장 함수 (0) | 2024.06.15 |
|---|---|
| [Oracle] 문자열 내장 함수 (0) | 2024.06.15 |
| [Oracle] 기초 (MySQL과의 소소한 차이) (0) | 2024.06.08 |
| [MySQL] Index 이해하기 (0) | 2024.06.02 |
| [MySQL] Join 알아보기 + 집합 연산 + 서브쿼리 (0) | 2024.06.01 |

